
Through the use of high throughput computing, NRAO delivers one of the deepest radio images of space
The National Radio Astronomy Observatory’s collaboration with the NSF-funded Partnership to Advance Throughput Computing (PATh; NSF grant #2030508) and the Pelican Project (NSF grant #2331480) leads to successfully imaged deep space and creates a first-of-its-kind nationally distributed workflow model for data-intensive scientific investigations.
Ten years ago, the National Radio Astronomy Observatory (NRAO) pointed its Very Large Array (VLA) telescopes toward a well-studied portion of the sky, searching for the oldest view of the universe. Deeper structures reflect older structures in space, as their light takes longer to travel through space and be picked up by telescopes. Radio astronomy can go even further, detecting structures beyond visible light. The VLA telescopes generated enough data that a single image of a portion of the sky resulted in two terabytes of data. Without the computing capacity to image the complete data set, it sat largely unprocessed — until now.
Researchers at NRAO knew that attempting to process this entire data set in-house was impractical. A previous computing run in 2016 using only a subset of this data took nearly two weeks of active processing. The high sensitivity of radio images requires a vast amount of computing to reach a final product, noted Felipe Madsen, an NRAO software engineer. The VLA telescopes are interferometers, meaning they point two antennas at the same portion of the sky; the differences in what these antennas provide eventually result in an image, Madsen explains. NRAO models and re-models the data to decrease the noise level until the noise is indistinguishable from structures in space. “This project is a lot more data-intensive than most other projects,” Madsen said.
Curious about how high-throughput computing (HTC) could enhance its capacity to process data from the VLA, NRAO joined forces with the Center for High Throughput Computing (CHTC) in 2018. After learning about what HTC could accomplish, NRAO began executing trial runs in 2019, experimenting with HTC. “Four years ago, we were beginning to use GPU software to process our data,” Madsen explained. “From the beginning, we understood that to be compatible with HTC we needed to make changes to our systems.”
Each team learned from and made improvements based on insights from each other. Greg Thain, an HTCondor Core Developer for the CHTC, met with NRAO weekly to discuss HTC and changes both parties could make. These weekly meetings resulted in the HTCondor team making changes to the software, eventually improving the experience of other users, he said. OSG Software Area Coordinator of CHTC Brian Lin helped NRAO manage their distributed infrastructure of resources across the country and transition workflows from CPUs to GPUs to make their workflows more compatible with HTC. Through distributed HTC, NRAO was able to run workflows across the country through the Open Science Pool (OSPool) and PATh Facility.
At NRAO, Madsen developed the software to interface the scientific software in the LibRA package developed by NRAO Algorithms Research & Development Group with the CHTC infrastructure software. This separation of software allowed the two teams to solve problems that arose in real-time as the data began to transfer across sites nationwide.
By December 2023, both parties were ready to tackle the VLA telescope deep sky data using HTC. Transitioning workflows to nationwide resources led to data movement issues, struggling to move efficiently from distributed resources. The December 2023 image processing run relied upon resources from the Open Science Data Federation (OSDF) and the recently funded Pelican Project to speed up data transfers across sites. Brian Bockelman, PI of the Pelican Project, and his team helped NRAO improve data movement using the OSDF. “Both teams were working to solve problems as they were happening,” Madsen recounted. “That made for a very successful collaboration in this process.”

Ultimately, the imaging process was 300 times faster than without using HTC, NRAO reported in a press release describing the project. What had previously taken two weeks now took only two hours to create the final result. The final image turned nine terabytes of data into a single product of one gigabyte. By the end, the collaboration resulted in one of the earliest radio images of the Hubble Ultra Deep Field.
The collaboration that led to this imaging is even bigger than NRAO and CHTC. The OSPool, which provided some of the computing capacity for the project, is supported by campuses and institutions across the country that share their excess capacity with the pool that NRAO utilized. For this project, 13 campuses contributed computing capacity, from small institutions like Emporia State University to larger ones like San Diego State University.
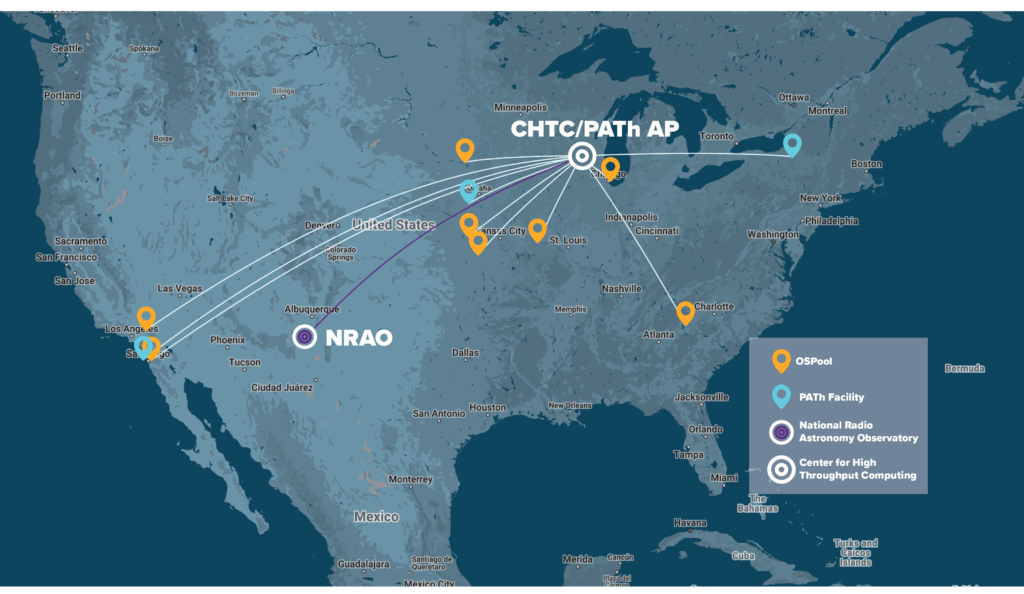
The December 2023 run and the working relationship between CHTC and NRAO revolutionized information available to astronomers and proved that HTC is a viable option for the field. “It’s useful to do this run once. What’s exciting is doing it 30,000 times for the entire sky,” Bockelman said. Although previous radio astronomy imaging workflows utilized HTC, this run was the first to image data on a distributed workflow nationwide from start to finish. Moving forward, NRAO and CHTC will continue covering the entire area of the sky seen by the VLA telescopes.
Madsen is enthusiastic about continuing this project, and how the use of HTC is revolutionizing astronomy, “I’ve always felt like, in this project, we are at the cutting edge of the current knowledge for making this kind of imaging. On the astronomy side, we can access a lot of new information with this image,” he said. “We have also imaged a data set that was previously impractical to image.”